4P Strategy: AI-based Solution Recommendation for Incident Management

In my previous blog I had discussed techniques to reduce “alert-storms” triggered by AI based monitoring systems. This happens to be one of the main problems that the SREs struggle with, leading to alert fatigue and distraction from critical problems. In this context I had mentioned about Event Ranking and Alert Correlation which helps SREs and ITOps focus on only the high severity events and filter out the noise. This makes the task easier for SREs but they still need to debug the problem and identify the root cause and also come up with a potential fix. Both these steps are still overwhelmingly manual and requires substantial understanding of the domain for full automation. In this blog I will primarily focus on solution recommendation which gives useful suggestions to the SREs on how to fix problems pro-actively. I will also touch briefly on fault localization which is important to perform before we can suggest or recommend solutions/actions.
Fault localization
As the name suggests, Fault Localization is the technique by which we can find out the precise location of the fault. By location we usually mean the service or the instance where the fault started. Once the fault is localized we can gather forensic information from that location (instance/service) and its neighborhood to triage the problem.
We assume that, at this point, alerts have been correlated and a ticket is available in the incident management system which describes the ongoing problem. We also assume that a topology is available to understand service dependencies. In the absence of topology we can create a causal dependency graph by temporally correlating events from history.
The fault localization can be done using the knowledge of topology (or causal dependencies) and the temporal sequence of constituent events. The localization technique can be further enhanced to provide the most likely fault propagation path and impact radius. Additionally we can also estimate the ETA of the fault at the various nodes in the fault propagation path which gives SREs some lead time to prevent an outage.
I will discuss about these techniques in more detail in a subsequent blog.
Solution Recommendation
The ultimate goal of all AIOps system is “automated healing” which involves performing a series of actions which will fix the problem and prevent outage. If this can be fully automated we successfully reduce manual intervention to zero. However, even with very sophisticated techniques, it is difficult to achieve 100% automation in ticket resolution. Firstly there is the risk factor — a wrong set of actions can cause irreparable damage to the system. Secondly, even if we are fairly confident about the next course of action, because of subtle differences in the deployment environment (e.g. OS, config etc.) the automated actions may not work correctly. As such, it is often advisable to update the incident with suggested recommendations for next course of action and let SREs or ITOps take the final call. We will, therefore, limit the scope to providing solution suggestions only.
In this context, it is important to note is that most problems in AIOps are repetitive, following a 80–20 rule. This means that at least 80% of the volume of problems belong to only 20% of the distinct problem types or classes. These problems are easier to solve and recommend using ML as there is sufficient training data. The remaining 20% contains infrequent problems belonging to a large number of distinct problem types and require slightly more advanced ML techniques.
In this article I will talk about a few techniques using which we can provide solution recommendations for both types of problems.
Human assisted technique:

In this approach the historical incidents are clustered into a discrete set of problem categories. The clustering is done based on the sequence or pattern of events seen in historical data. Additionally, we can mine unstructured fields like problem description, root cause, actions etc., if available.
Once the problem categories have been identified, each category is associated to one or more solutions (or list of recommended actions) to create a problem category->resolution(s) mapping. This can be done manually, with the help of SREs; or by extracting resolution information from incident management system. The mined resolutions can then be verified by SMEs and added to the list of solutions for a problem category after curation. Verification is often the better approach as it is easier to verify rather than to examine each problem category and come up with a curated resolution from scratch.
At runtime the incoming ticket is first classified into a known problem category and then the resolution(s) mapped to that category are returned. The returned category and results can be fed back to the incident management system for enrichment of training data.
This simple approach can be used effectively to automate suggestions when the closing remarks (about root cause and actions taken) are not available for closed tickets. The approach works fairly well for the most commonly seen problems which forms well defined clusters.
Incident similarity based method:
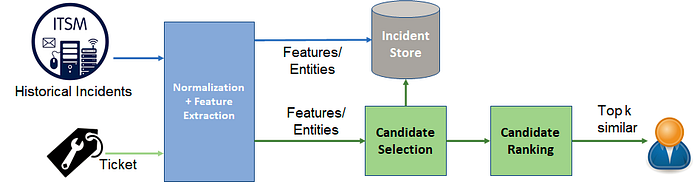
The incident similarity technique uses a somewhat similar approach. However to reduce manual intervention, we suggest similar tickets with recommendations instead of suggesting resolutions directly. The primary insight here is that, if two incidents are similar, they will have similar resolution.
To implement this, we need to extract features from the problem ticket. These can be metric based features like metric-type (CPU, disk, I/O, memory etc.), trend (upwards/downwards) etc. or log based like error codes (e.g. ORA-04030), template distribution patterns etc. Additionally we can extract entities like component/sub-component (e.g. MySQL, Tomcat, WebLogic etc.), fault location, problem description, incident type (if available) and so on.
The similarity between tickets can be obtained by comparing across all feature dimensions and computing a suitable distance metric like cosine-similarity or Jaccard distance. Additionally, we need a ranking step to rank tickets based on the quality of recommendations (tickets with better or more detailed resolution steps or action phrases will be ranked higher).
This approach is feasible for most practical scenarios when there are a lot of incidents for training, but only few of them have root cause or resolution information. However, for infrequent problem classes we still may not be able to get good suggestions.
Web based recommendations:

Using the techniques mentioned above we can only give solutions which are already available in historical tickets (or manually curated). We cannot generate an altogether new solution. But it may be needed in cases where historical tickets are not able to provide us with a high confidence answer. In these cases we can fall back to web search. To search effectively for a solution, we need to extract entities like metric types/trends, log messages, error codes etc. using NLP. We can then use the extracted entities to formulate a query and search for possible solutions in the web. Finally, we can rank the results based on relevance. However one caveat here — these solutions are likely to be generic and may not be a tailor-made solution readily useful to the end user.
This approach can be used for infrequent problems, for which there is insufficient training data or lack of resolution information. By combining the 3 above techniques we can get decent results for most problems. Next, I will talk about some advanced techniques which will help in further improving our results.
Learning from user feedback and comments:

To improve the quality of resolutions over time we need to incorporate feedback continuously from past incidents and improve our recommendations using ML . This requires mining unstructured entities from closed incidents (e.g. root cause, actions taken etc.) for continuous learning.
From the closed incidents we can understand which of our previously recommended solutions were useful and which were not. This information can be mined from the closing remarks of the ticket and fed back to our model, as shown in Fig 4. The solution recommendation module can use any one (or a combination) of the techniques described above. The recommendations can then be blended and re-ranked using a suitable ranking mechanism (e.g. Learning-to-Rank or L2R).
Additionally, we can also implement an explicit feedback mechanism. The explicit feedback can be provided in 2 ways: either through UI, where the user can provide information on whether the suggested action was useful or not; or using a free text web form where the user can type in an alternative action or solution which worked for him. The alternative suggestions can be added back to the solution pool (after de-duplication) to enrich the training data. The advantage of this is that the explicit feedback can be mined even in the absence of a proper ITSM tool.
Generative technique:
All the techniques I have discussed so far are based on information retrieval. There is another class of state-of-the-art AI/ML models which can be used for solution recommendation viz. generative models. In this technique we try to generate a solution instead of choosing from an existing set or searching the web. This can be done using generative sequence-to-sequence models (like LSTM).
The generative technique uses an approach similar to the machine translation problem. We train the model using tuples of the form: <problem, solution> from closed incidents. The model first encodes input sequence(problem) into an intermediate form which is then decoded into the output sequence(solution). In the process, it is possible to understand the problems at a deeper semantic level, so that a meaningful solution can be constructed. As such, we can not only suggest solutions for Tier-1 problems but also Tier-2/Tier-3 (higher escalation levels), requiring deeper domain knowledge.
Although generative models are the state of the art in research, they are still to be adopted widely in industry as it requires a lot of data to train for reasonable accuracy. However, if we have a lot of incident tickets to train (>1million) and most of them have detailed resolution steps we can consider this approach.
